
LeSS in Lean Times
In a world defined by change, adaptability is our greatest asset. This case study shares the story of a financial services company that weathered the storm with grace, resilience, and innovation.
Don't need all the detail? Then scroll straight to Sprint 2 - Self-Selection, Sprint 4 - Focusing on one thing or the Lessons Learnt sections.
This case study describes the agile coaching approach to unprecedented change in the business environment surrounding a mid-sized financial services company, pivotal in wealth management. It delves into the IT team's journey to resilience and adaptability as they navigated turbulent market conditions, a changing IT landscape, and personnel transitions. Discover how the organisation embraced the LeSS framework to provide a stable foundation for their teams and effectively respond to the dynamic forces shaping their industry.
Background
Most people remember the chaos of 2020-2022 when Covid changed the work landscape for the world. However, New Zealand did not really feel any financial effect until mid-2023, when the country ran into the first technical recession for over a decade.
In the midst of this, one mid-sized financial services company, which is the backbone of wealth management in NZ, found itself needing to focus on resilience and pivoting quickly in order to respond to the rapid market changes.
Over the previous few years the organisation had grown significantly and in the IT area, agile techniques had been haphazardly introduced to help focus on business goals and manage the flow of work to capacity. The approximately 30 people working in this particular area of IT had been operating agile-ish for several years. Some were in formal teams, some were not. So they decided to get an agile coach to help them get back to being self-managing teams creating customer-focused value. After a refresh of the principles and values, these 30 people self-organised into four separate teams coordinating and collaborating to get the work done for this one area of the company.
After the teams involved had been running as fully-functional Scrum teams for 8 months they had smoothed out their processes, got into a good rhythm, delivering planned work into production every sprint, and changing and improving their process as they went. However, this smooth road was not to continue …
Context
In April/May 2023, enter ‘turbulent times’! Several factors coincided to mean that these teams needed to significantly change the way they were operating so that everyone in the teams could be adaptable and resilient in the face of the environmental changes happening in both the business sector and the internal IT landscape:
A new technology platform was coming in to replace the existing spaghetti of in-house applications, integrations with external applications and vendor-supplied services. The set of skills needed in the future would be different than they had today.
Mid-2023 market nervousness following the non-covid-induced technical recession.
Management had made it clear that no new features would be available to the business people until the new platform was in place (fixes and urgency items only).
Teams shrinking as several team members left to follow other opportunities both internally and externally; especially one of the two Product Owners was moving to a different part of the business.
Key-people risk was high - many people were the only person to know about a particular system/technology.
As people left they were not being replaced - the load on existing staff was increasing so the remaining teams were told to amalgamate to be one team.
People on all levels have significant worries in times like these:
Executive leadership - “We need this change for strategic reasons“.
People in the middle - “We are required to implement this change - but we still need people to be happy and avoid loading them with a whole lot of new processes”.
Teams - “We experience the impact very strongly, it affects us day to day”.
Management wanted true agility - to be able to pivot using these high-performing people, as needed, to adjust with changes in market demand, availability of the new technology platform and the inevitable short-falls in functionality when adopting a new platform out of the box.
Challenge
So how do they help all the levels with their key needs at once?
Executive leadership - provide true agility, the ability to pivot and point these teams at the current business problem, as the need changes over the next few months to years.
Business people - provide smooth and consistent support and service whilst moving from old to new technology and business processes.
Teams - provide security and safety during turbulent times
With a lot of experience in the old technologies, the challenge was, how to re-align multiple (Scrum) teams to this new technology practically, quickly, culturally and still look after the old technologies at the lowest overall cost and impact - essentially they needed a “change shock-absorber”.
The Agile Coach put the LeSS option in front of all groups as a way forward in these turbulent times rather than experience the alternative, which was re-inventing how we do things as they went along and a difficult process of trial and error to come up with techniques that would make it workable for everyone.
Solution
The LeSS framework gives a set of techniques which have been tried and tested with many organisations by hundreds of teams, to give adaptability and resilience, a bit like a vehicle built for bumpy terrain. Since it is based on a solid foundation of Scrum, this was not too much of a jump for teams already used to that framework. Since it had answers for some of the key questions in everyone’s mind when trying to cope with such sudden and massive change, they decided that this would be a good place to start from. It may not make the road any smoother, but gives you some comfort in the way you drive along it!

LeSS Framework
Lining up a LeSS approach
Initial preparations
After some learning sessions on what the LeSS framework looks like, the teams basically learnt by doing. There were so many questions to still be answered, e.g.
How would the teams organise themselves?
How will Scrum Mastering work?
Service Desk process - how to get customer questions answered?
How does refinement work?
When/how should we start?
How do we know stories are Ready?
How do we know we’re Done, across teams?
Who will have to go to which standups?
Over the course of 10 days (before the next sprint start), there were many small-group discussions on these and other topics to get ready for an initial team kickoff where they could set their own expectations and answer these questions together.
Nearly all members were in person for the kickoff session, where most of these important questions were discussed. Discussions were in-depth and consequently they didn’t get through all the answers in the half-day that had been set aside. However, the resulting team charter, Definition of Ready and Definition of Done were put on the now-one-team’s confluence page.
Learning: Don’t try to squash a whole-team kickoff into half a day!

Sprint 1 - One backlog
They started with ONE backlog for all the work. This is core to the LeSS team’s focus.
This was harder than you might think, because they were not using LeSS for its intended purpose of many teams -> one product; they had many many technologies and products serving similar but slightly different sets of customers (although all within the one department). This meant the Product Owner, who had previously handled one team’s content, had to come up a level in detail and get to know the needs and demands of the other stakeholders and the technology that serves them. This was easier, in some ways, for them as there was less story-level detail needed, but harder to understand all the technologies and align on the needs of all the department’s stakeholders. It also meant the teams had to step up to get even more involved with shaping the stories than they already were.
The teams stayed in their existing structure for the 1st sprint after amalgamating the backlog in order to make the transition easier for the team members.
Learning: Be very clear on your priorities across all stakeholders - if the business people are not clear, the teams don’t know which work to pull first
Learning: The Product Owner in LeSS cannot be in the detail of the work - the team has to step up & take advantage of the BAs they have
Learning: It is worth changing incrementally to reduce impact on the people
Joint refinement
They tried joint refinement, as per the LeSS prescription, with small teams rotating around the top items on the backlog. It had to be virtual so that they could include everyone who was in different cities. In LeSS, the teams rotate around the first few items in the backlog, working on all of them so that they are familiar with the work, whichever item they pick up.
In this instance they broke people into 3 sub-teams and worked on a collective miro board to rotate around the items. They split up the people with the same technology knowledge so that they could explain the work to the others in the sub-team. Each had about 10 minutes to describe the nature of the work and see if the group could say the item was ready as per the Definition of Ready.
These teams were jaded with too many meetings so they kept it to 1hr and did what they could in the time.
During the discussion, each team crossed off as many DoR items as they could, given their knowledge of the work. As you can see, some work was close to ready and some was not. Having spent 30 minutes rotating around the three items, it became very clear very quickly that there was far too much for team members to learn about unfamiliar pieces of work before they could really institute this way of doing refinement. The team decided that some ‘intro to’ sessions would need to be held in the upcoming sprint before they could even start to work across the other team’s area.
It was a useful experiment, but quickly surfaced the truth that it’s hard to learn new technologies and the existing problem of people working across too many technologies already.
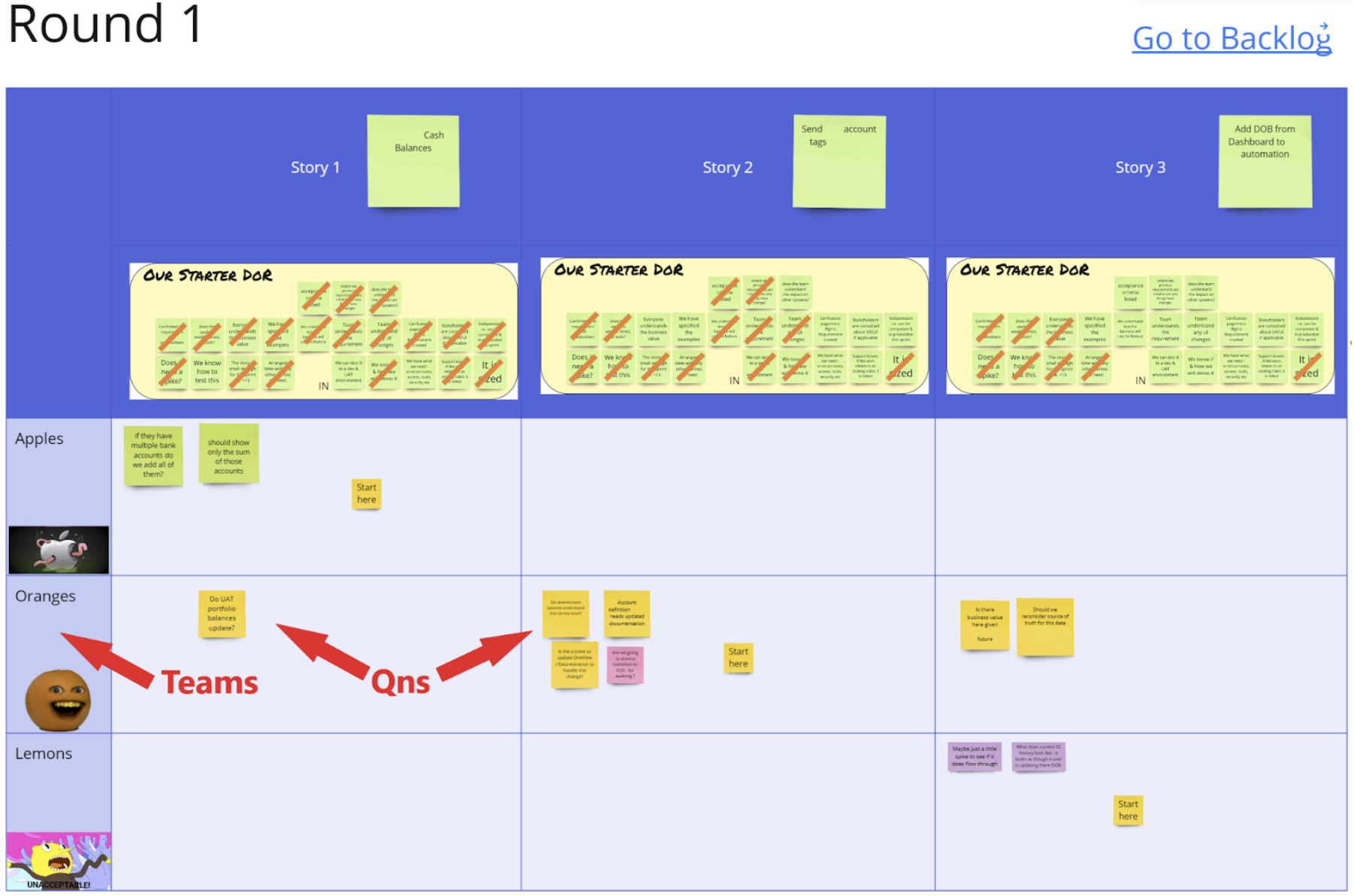
Learning: It’s hard to do refinement on work you don’t normally handle. Allow time and provide knowledge sharing sessions to get others up to speed.
Learning: If refinement doesn’t get work ready before the sprint, planning takes MUCH longer.
Learning: If refinement doesn’t get work ready for the sprint, planning takes MUCH longer
Sprint 2 - Self-organisation and supporting a One-team approach

Self-selection as standard
Starting Sprint 2 they incorporated a self-selection workshop as part of the regular Sprint Planning 1 session. This is where the teams choose how they want to form, who will work together on the highest priority work. This was not unfamiliar to them as they had done this 8-months before when they had formed into the existing teams. At that time, it was always expected that the teams would re-form later on, so that it was not a once-and-done experience.
After hearing about the relative priorities of the business needs from the Product Owner, the people gathered into small groups focused on the current highest areas of priority. It was expected that this would change sprint by sprint, given the pace of change in the environment around the business e.g. one sprint ‘customer migration’ and ‘new platform’ were the priority work, the next ‘onboarding’ and ‘new platform’ might be.
Fortunately, the teams had done a self-organisation workshop before and had been asking when they might do it again. This provided the ideal opportunity to make it a regular practice.
So the teams formed based on some key principles:
Do what’s right for the organisation
Pair on everything
Share - take turns learning
Do what you’re interested in
LeSS has the concepts of long-lived teams, as well as Travellers. These teams had been long-lived, but the expectation was that everyone could choose which work to gather around each sprint i.e. be a Traveller and nominate which mini-team you wanted to be dedicated to each sprint. Some people took the opportunity to spread their wings but most people, initially, stayed pretty much in their existing teams; there’s nothing so strong as habit! However, this did not remain the same in the next few sprints.
Learning: Self-organisation must include the concept of Travellers if you want real agility; they are essential to one-team resilience.
Cascading standups
As everyone involved didn’t know who would be in which team each sprint or how many teams they would end up with, they instituted cascading standups i.e. there were several slots 9.15-9.30, 9.30-9.45, 9.45-10am. Each team that formed in the self-organising session would claim one of the slots.
Ensuring support was still covered
People had grouped around the priority work but had not settled on how the essential BAU support work would continue to be handled.
Prior to this, support tickets were initially received by one support-receiver who dealt with what they could and identified when team input was required. However, two problems arose:
The tickets were getting stuck at the point where team input was needed as the mini-teams were concentrating on the planned work.
When that one person was sick/away, others were reticent to step in and deal with the tickets. They had set up another single point of failure.

Following Sprint Planning, the team gathered to address the first point and decided that a ‘pair triage time’ would happen after all the standups, with all the team members who could be needed to address tickets.
PURPOSE: to see whether they were easy fixes (do them that day) or longer investigations which needed to go into the backlog to be prioritised.
To cover off the second point, the support-receiver role was backed up in the interim by several people who would step into that role if asked but it was a risk that was not fully resolved as several of these back-ups were leaving (ending contracts, maternity leave etc.) in the next few weeks. However, it was good enough for an experiment for now.
Learning: People forget about their duty to continue to cover support work when given freedom to move around, especially if they were the key person risk for a technology.
Learning: When allowed to resolve their own problems, teams come up with novel solutions.
Merging cultures even within two teams that work closely together
One surprising finding was that, even though these teams had worked closely together, there was still a culture shock and a lot of compromising had to be done about how to work as one team. Primarily around:
Using Jira (the backlog tool)
Sizing work
They worked on different sub-systems and had developed their own way of working - one using a lot of automation in Jira, the other not, one using a lot of pair programming, the other not. So, although they were closely aligned through their former product owners, happily self-managed and coordinating when necessary, when asked to be agile & able to pivot together, it requires more than just collaboration.
There was a pocket of agility within each team, but there wasn’t a holistic agility until they dealt with things like one backlog and one product owner. When you ask teams to scale up one notch, culturally, suddenly these things get in the way - the teams have to work through it. Each team compromised some of the way they worked to ensure everyone could contribute to everything as needed - truly being able to pivot together, as one team.
Learning: True scaling of agility will bring to the surface the silos that still exist across teams.
Sprint 3 - Make the future a reality
In sprint planning for sprint 3 they got their first true glimpse into the future with an intro to the new technology platform timeline and overall plan. Following the identification of the priority work, the teams truly self-formed - initially into 4 mini-teams, then two amalgamated to make 3 mini-teams. The actual makeup of the teams was probably a little skewed towards the new technology/opportunity of the new tech, but that wasn’t surprising, technologists being what they are!
Again, the self-selection principles were:
Do what’s right for the organisation
Pair on everything
Share - take turns learning
Do what you’re interested in
The Product Owner shared with us what work was really needed by means of a pie chart showing the different types of work undertaken. This was to help people choose, in the self-organisation session, which work to cluster around. This was represented on the working board by circles, with a priority number according to the businesses needs, with a list of associated skills required in order to get the work done.

Step 1 - Identify areas of work and relative priority
From there everyone could put themselves into one of the circles, representing the work they could best contribute to for the current sprint (orange stickies). If someone opted to go into two circles then they put a second (green) sticky to represent where their first priority lay (see more on this below).

Step 2 - Allocate yourselves to a circle
Interestingly, it came out in discussion that some work was going to involve the whole (big) team, so a new circle of work emerged which was for ‘everyone’ i.e. cross-skilling sessions, ‘intro to’ sessions. This was added to the backlog and the sprint.
Learning: Seeding the concept of self-organisation being the normal way of operating across the one-team, brought a resilience to the collective group, because they knew they would be in control of how they organised within that, when the business shifted priorities around them.
Splitting yourself has impacts
People were concerned about attending many standups, so they really had to consider whether to split themselves across teams. If they decided to be in two circles, they had to attend more than 1 standup because they are contributing to the work of both teams.
The 2 questions were posed:
Is there enough capability in this circle to complete the priority work?
Is there enough work in this circle to justify this team?
All of this led to a slight adjustment:

Step 3 - Rationalising the people vs work
There was insufficient work to keep one small team busy so it was decided to merge with another team and work together, which also provided knowledge sharing. This also reduced the number of people split across mini-teams. You will notice that nearly everyone was in one team - the ‘new technology’ work.
Each team then selected one of the cascading standup slots for that sprint. If you were in only in one team you went to one standup, but if you were across two teams you had to go to both standups. This policy aimed at helping people to stick with one thing for one sprint.
Learning: Splitting yourself across teams means overhead in time and effort.
Learning: Technologists will flock to the new, shiny thing - they need to balance autonomy with alignment to purpose
Learning: All the teams found the smaller team sizes were very effective for getting the work done. e.g. standup was far more focused and engaging because you were more closely involved in all the work and the goal of the sub-team.

Scrum Mastery
One of the big questions at the start was, ‘How is Scrum mastery going to work?’. All the former, proposed, and interested Scrum Masters got together and discussed options. They drew many different structures on the board and worked through what was feasible.
What was selected was the (new) single Scrum Master would operate across the one-team supported by the coach, but each mini-team would nominate a mini-team Scrum Master (SM) who would help by facilitating their sessions. Mini-team SMs would be SM for that entire sprint, and may change per sprint. However, the long-term goal was to move to one-team, one SM, with the main SM role rotating across different people every few months.
After the Sprint 3 self-selection workshop, each mini-team nominated their mini-team SM for that sprint.
Overall retrospective
In Sprint 2 & 3 they instituted the LeSS Overall Retrospective where everyone is involved in a discussion about the overall environment and what experiment they’d like to try to change the systemic issues around ALL the teams.
In order to do this the coach ran a retrospective using systemic modelling, which brought out the issues people were seeing, and some of the factors they saw interacting to cause them. The first time using systems thinking, this is very different for everyone who is used to thinking about making changes only in their team. Although the model was useful, it only led to similar changes that would probably have come out of a regular retrospective.
Learning: Systemic thinking is a skill. You may not get earth shattering changes the first time. You may need to encourage people to try something really different.
Sprint 4 - Truly one-team, focussing on one thing

At time of writing, they were just starting sprint 4.
From the previous sprint, the teams learnt that support still needed to be done, and that there wasn’t actually much for them to do in the new technology for a while. So, the challenge was put to them to reduce the support call backlog by concentrating on long-term fixes which would prevent recurring issues from arising. The sprint goal being - “to reduce ongoing support work”. Now this is something that all development teams long for, and they were being given a golden opportunity.
#1 priority was reducing ongoing support (service desk) work. The picture below shows what they were expected to do this sprint - at least 50% of time spent on service desk tickets:
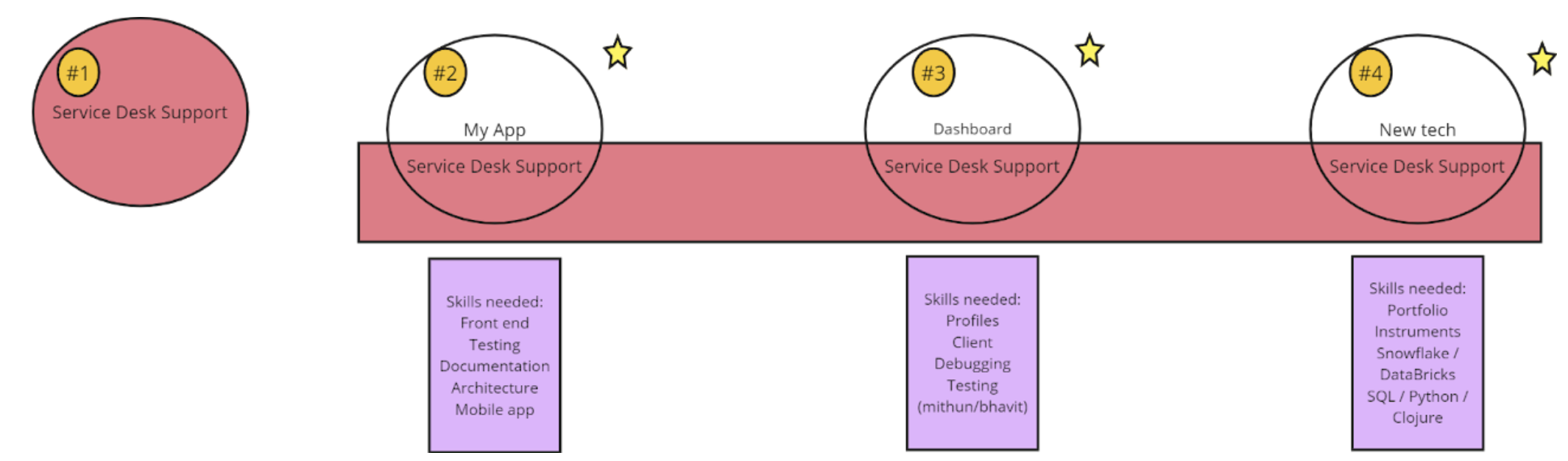
The team answered the call, more than the leadership could have asked for. In Sprint Planning, the Product Owner and team really debated whether ANY of the work on the backlog needed to be looked at, at all! In order for the team to truly concentrate on fixes that they never had time to get to, only one item was brought in from the backlog.
Therefore, they reasoned, they didn’t need different teams to work on different things - they were going to be one team, working together on the long-term solutions to the support issues. The above picture was out the window! There was only the #1 team.
They then gathered around all the support work that was known about - whether from the current support calls, from developers heads (those nagging fixes you’ve always wanted/meant to do) or from the main backlog. It was visualised, and group-categorised as to a realistic impact/effort matrix (https://itamargilad.com).
During these discussions, team members raised several items “but what about……, don’t we have to get that done this sprint?”. Each was discussed and put aside when they reminded each other of the sprint goal - “to reduce ongoing support work”. What was outstanding was that there was one very smart person in the team who could be counted on to rebel against the machine, and ironically it was them that kept reminding the rest that they were going to be one team, with one goal this sprint - working on long term support fixes! It was brilliant! Give a rebel an avenue to buck the system in constructive ways and they’ll be the best advocate you could have!
Learning: We need rule benders. The rebel is often the one to push for quality or to fix something that’s not working. If you give them the space to break the rules, they will lead the charge.

REMEMBER IT TAKES TIME!
So, these teams responded to a stressful time by being courageous, trying new things and tuning and adjusting as needed. Normal teams starting up with Scrum, take 4-5 sprints to become anywhere near ‘normal’ and settle into a rhythm and a steady flow. This was an unusual, stressful situation and a new framework, so this was just the beginning of the experiment - 4 sprints is not enough - but it was certainly enough to learn a whole lot about what works and what doesn’t if you really give teams the opportunity.
Hopefully, they’d proved they’d achieved the original aim to be ADAPTABLE and RESILIENT.
Conclusion
In conclusion, the case study outlines a remarkable journey of transformation undertaken by multiple teams during a period of significant turbulence and change. Faced with a convergence of challenges including the introduction of a new technology platform, market uncertainty, and team restructuring, the need for adaptability and resilience became paramount. The case study demonstrates how a solution rooted in the Large-Scale Scrum (LeSS) framework was implemented to address the diverse needs of different stakeholders and levels within the organisation.
Through a systemic approach, the coach and the teams embarked on a path of change, seeking to align themselves with the LeSS framework. The framework's principles, built upon the foundation of Scrum, provided a set of tried-and-tested techniques that enabled the teams to navigate the complexities of their situation. The journey encompassed key phases such as initial preparations, stepped introduction of techniques, self-organisation, and focussing around a collective goal.
Crucially, the case study highlights the challenges encountered and the learnings gained throughout the process. These challenges included merging the cultures of closely-related teams, managing the balance between ongoing support and new initiatives, and embracing self-organisation as the norm. The process also revealed the significance of culture change and having rule-benders, individuals willing to challenge existing norms for the sake of innovation and quality.
The case study underscores the fact that transformation takes time and effort. While four sprints marked a significant step forward, it is acknowledged that the journey towards a truly adaptable and resilient state is ongoing. The presented journey demonstrated the power of collaboration, experimentation, and embracing change as a means to navigate complex scenarios.
Ultimately, this case study serves as an inspiring example of how an organisation can respond to unprecedented challenges with agility and ingenuity. By leveraging the LeSS framework and fostering a culture of continuous improvement, the teams made strides towards their goal of adaptability and resilience, setting a valuable precedent for others navigating turbulent times.
Lessons learnt along the way
Don’t try to squash a whole-team kickoff into half a day!
Be very clear on your priorities across all stakeholders - if the business people are not clear, the teams don’t know which work to pull first
The Product Owner in LeSS cannot be in the detail of the work - the team has to step up & take advantage of the BAs they have
It is worth changing incrementally to reduce impact on the people
It’s hard to do refinement on work you don’t normally handle. Allow time and provide knowledge sharing sessions to get others up to speed.
If refinement doesn’t get work ready before the sprint, planning takes MUCH longer.
Self-organisation must include the concept of Travellers if you want real agility; they are essential to one-team resilience.
People forget about their duty to continue to cover support work when given freedom to move around, especially if they were the key person risk for a technology.
When allowed to resolve their own problems, teams come up with novel solutions.
True scaling of agility will bring to the surface the silos that still exist across teams
Splitting yourself across teams means overhead in time and effort.
Technologists will flock to the new, shiny thing - they need to balance autonomy with alignment to purpose
All the teams found the smaller team sizes were very effective for getting the work done.
Systemic thinking is a skill. You may not get earth shattering changes the first time. You may need to encourage people to try something really different.
We need rule benders. The rebel is often the one to push for quality or to fix something that’s not working. If you give them the space to break the rules, they will lead the charge.
We welcome your comments.